

AI adoption is accelerating faster than regulation can keep up. While lawmakers and platforms attempt to control data usage, outputs, and risks, modern AI systems continuously adapt to those very constraints. This article examines why regulating AI is inherently paradoxical—and how guardrails, benchmarks, and adversarial models turn governance into part of the system itself.
If it were not 2024, this year marks a peak in the buzzword frequency for "AI". Rarely has any information-based platform been spared, from social media to most editors. From AI-generated Content to the use of agents for complex tasks. AI is making our lives much easier, but there can be no light without the dark.
The problem comes from different aspects: Either the quality or value of the results is below expectations, or the data used for training is questionable, which can furthermore lead to questionable or even unethical results. One of the fundamental dimensions of how to measure labor is time. If you can have something very quickly, the price drops. A masterpiece of art might take hours to paint, though there is a scaling factor around the artist, such as overall experience and available tools and materials. On social media, AI-generated videos are like a flood. And it works: some posts have something funny or fascinating (did you hear of Shrimp Jesus?). Generating such content takes only a few minutes, if not seconds. That's a rate that normal content creators can not keep up with. They are firing content like a Machine Gun - if only one post gets enough likes, the reach is growing.

Additionally, the usage of AI Content and possible violations are still not legally regulated. In the beginning of the year the German author Marc-Uwe Kling started a campaign which collected votes to forbid DeepFakes of real person. This might also have been a marketing stunt, since his thriller Views (which I suggest reading) was also published recently and covered a very similar topic. His campaign might be the most public one, but by far no the only one. For e.g., in March a petition was raised with the same claim. Citizens have concerns and ask for some kind of regulation. A very first step to protect human rights and safety is the EU AI Act. However, many companies see it more as a burden, such as GDPR. So while the legal situation in developing and the usage of AI becomes as normal as "googling", there will be regulatory approaches to ensure quality and safety among those tools.
How can AI be regulated?
Basically each data driven inductive machine learning model can be seen as a black box model.
.png)
In the training phase, the stimulus is the training data, and the response is the result of the epoch. In the inference phase, the stimulus (for an LLM) could be a prompt, for which the response is the completion of the prompt or the creation of an answer. The black box model is not so far-fetched, since most neural networks are trained this way and neural networks are the foundation stones to large language models and diffusion models.
One way to regulate a model is limiting it's capabilities by reducing it's training data. Unfortunately, the law is not always equally enforced when it comes to data usage violations. For example, Llama was trained using pirated datasets. Mark Zuckerberg seems to be aware of this, yet there are no consequences for Meta. It gives not the best vibes if one compares this situation with the story of Aaron Swartz, who made a large set of academic journal papers publicly available, was arrested, and committed suicide afterwards. This article is not about him, but the contrast of both stories gives a good example of how different one can see the "correct" usage of data. Eventually, the stakeholders and economic drivers will foster the field. Taking that into consideration, a regulation of a training datasets is not very likely - at least not in near future.

A regulation of the output is already partially happening. Have you ever tried putting a Marvel superhero in your recently taken photo? Some Guardrail tool is intervening to protect content policies but not only that: A solid amount of LLMs were trained on intellectual property, which could call several law suites, if a tools like ChatGPT actively encourage the use of it. Such tools can be simply driven by rules and keywords, for example, looking at Guardrails-AI. Why don't we use LLMs against LLMs? Actually, we do, for example, LamaGuard is using an adversarial LLM approach. However, there needs to be a benchmark or ground truth so that LamaGuard can do correct classifications.
But also, some social media platforms had an "do not use AI generated content" policy. No guardrail tool is involved here, but a classifier to detect AI generated content is required as well.
This is exactly where our paradox begins...
Why can't you regulate AI
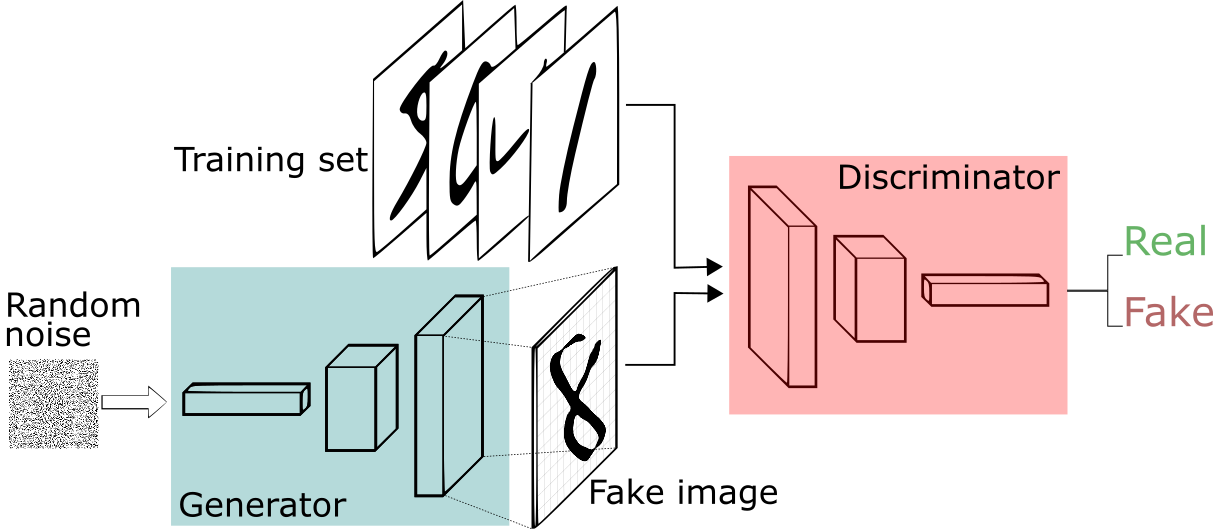
Can you remember GANs by Ian Goodfellow? That architecture used a discriminator that needed to be convinced that an image was not fake, though it was generated. In that approach, the generator became better at faking it until the discriminator could not distinguish between fake and real images.
But we can go even a step further back: What is required if you train a supervised model on data? Groundtruth. What is a cat? What could the next character be? What is a real-world image? What text violates intellectual property? So you need some kind of a benchmark, a reference. And this is where we have a uroboros situation...
Regulation as a Benchmark
Even a set of rules provided by the EU will sooner or later call for vendors who are providing you solutions like: "Our tool can ensure that no real-world person is included in your generated images.", "Our guardrail mechanism ensures, that no IP is violated."
And once again, we have a discriminator to convince. Now we can optimize the generator for it and ensure our regulation violations won't be detected for a certain time. 😄
Do you agree or have an idea how this problem could be mitigated? Do you have a completely different opinion on this? Drop me a line at alfred.feldmeyer@squer.io or on LinkedIn. 😊 ☕️
